Chuting Xu

Applied Statistics in R/Python
I build reproducible R/Python pipelines that turn messy economic & genomic data into interpretable, decision-ready models—making statistical models work in the real world.
Open to collaboration on statistical modeling with interesting datasets—especially fairness-aware, robust models in data analysis.
Technical Toolkit: Python · R · Git · GitHub Actions · Snakemake · Docker · Conda · SQL
Why Applied Statistics?
Applied statistics sits in an interesting—sometimes awkward—middle ground. It isn’t pure math (our models are approximations) and it isn’t unconstrained machine learning (capacity isn’t a substitute for understanding). What it offers is a disciplined way to learn from data and act on it: pose a question, build a workable model, confront it with evidence, quantify uncertainty, and update what we believe.
I work with the humility that models are only useful when they’re fit for purpose, their assumptions are explicit, and their diagnostics are honest. I’m comfortable mixing interpretable statistical models with algorithmic tools when they clarify the signal, transfer across datasets, and support real decisions—very much in the pragmatic spirit Breiman urged.
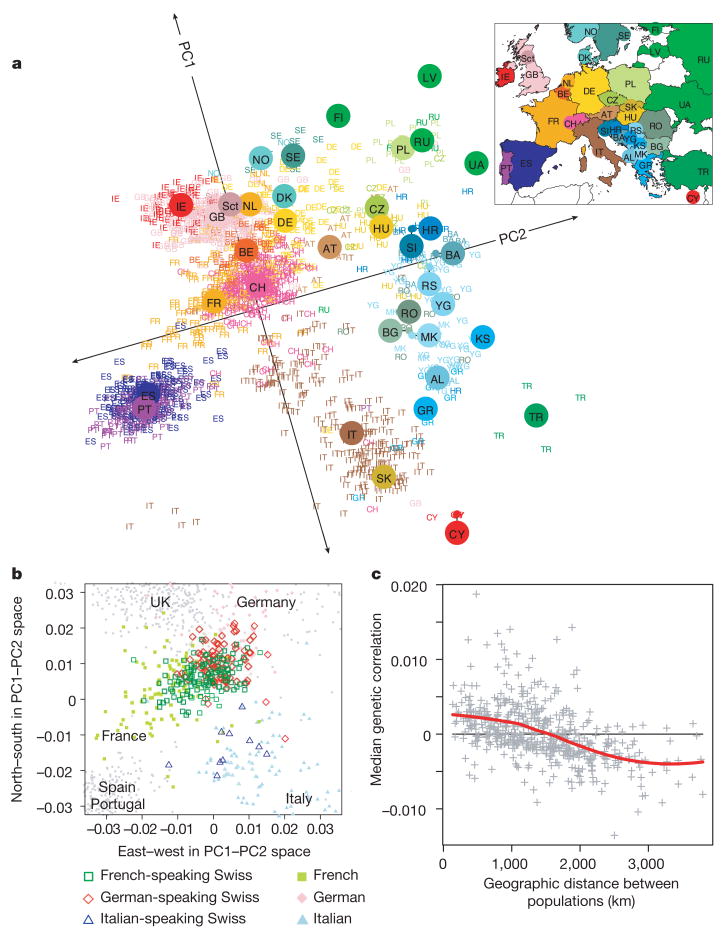
The payoff is insight you can test. A favorite example: principal component analysis on large-scale European genotype data essentially recovers a map of Europe—evidence that careful modeling can reveal stable structure beneath complexity.
View the PCA figure
Reference: Novembre J., Johnson T., Bryc K., Kutalik Z., Boyko A.R., Auton A., Indap A., King K.S., Bergmann S., Nelson M.R., Stephens M., Bustamante C.D. (2008).
“Genes mirror geography within Europe.” Nature, 456:98–101.
doi:10.1038/nature07331
{kind=link}
And when results look meaningless or ugly at first glance, that’s a cue to keep going—re-specify, re-check, and let evidence sharpen the picture.
“The truth, however ugly in itself, is always curious and beautiful to seekers after it.”
— Agatha Christie, The Murder of Roger Ackroyd
Past Projects
Explore a few projects that show what I enjoy about applied statistics—turning real economic and genomic questions into interpretable models.
Gene Expression from Chromatin (GM12878)
- Problem: Predict ON/OFF status and expression level of genes from chromatin features around TSS (CAGE-based), validating a simplified Dong et al. 2012 pipeline.
- Approach: BigWig histone/DNase signals → TSS-centric bins; D1 for bin selection, D2 for training; two-step models {LR/RF/SVM} → {Lasso/RF/MARS/SVR}; 10-fold CV.
- Result: Classification AUC around 0.9+; best two-step combo RF-Classifier + RF-Regressor with strong RMSElog and Pearson correlation on chr1.
- Repro: R (tidyverse, randomForest/MARS); fixed seeds; `renv::init()` to capture versions; Quarto report renders end-to-end.
- Code · Report: Repo · Report
USG Analytics (Gold ETF Forecasting)
- Problem: Predict next-day Gold ETF adjusted close from market signals while avoiding leakage and overfitting on a small 2011–2019 dataset.
- Approach: Time series → supervised ML with 1-day lags + 7/30-day rolling means; models = RF, best-subset OLS, Lasso, Ridge; 10-fold CV; simple 4-model average ensemble.
- Result: Ensemble achieved the best error (MSE ≈ 1.44); RF the best single model (MSE ≈ 1.49); all beat the naive “yesterday = today” baseline (≈ 1.55).
- Repro: Python + scikit-learn; deterministic folds (`random_state=42`); save `requirements.txt`; add Binder/Colab badge.
- Code · Report: Repo · Report
Textbook Exercises
Rigollet — High-Dimensional Statistics (notes & exercises)
I work through the lecture notes by Philippe Rigollet (arXiv:2310.19244), posting selected solutions and short write-ups.
Exercises page · GitHub repo